NSQ and Golang Messaging Primer
In this post, we’ll look at how you can use NSQ in your golang applications to start leveraging messaging. Messaging offers the easiest way to build an async architecture, for which there are a number of benefits ranging from scalability to the reduction of cascading errors. In this post however, we will be focusing on how messaging can be used to decouple components in your software by looking at a couple of common patterns for doing so: work queues & pub/sub.
NSQ is a realtime, distributed, horizontally scalable messaging platform. Also, it’s written in Go and is distributed as two simple binaries (plus an optional admin web app and a collection of utility tools) so it is easy to install and keep up to date (no dependencies.) There are a slew of both official & community supported client libraries, and we will be using the officially supported go one in the examples below.
This post is divided up into four sections:
- First we’ll get NSQ running in a local cluster using Docker Compose.
- Next we’ll build a couple of simple Go apps to publish to and consume from NSQ
- Third we will look at how to scale the consumption of our messages using the Worker pattern
- Finally we will update our example to implement the Pub/Sub pattern
Follow along here, or clone the demo repo if you perfer
Running NSQ
The NSQ design is dirt simple both
to get running and to use. The recommended install layout is to run an instance of nsqd
alongside each service that is producing messages and to run a handfull of nsqlookupd instances
(3-5 even for very large installations) for message consumers to
discover the appropriate nsqd node with. To get everything talking to each other,
nsqd needs to be configured to register with each instance of nsqlookupd.
One thing to note here: the nsqlookupd instances do not discover each other.
This means that each nsqd instance will need to register with all nsqlookupd instances
and if you need to replace an nsqlookupd instance and it gets a new address,
you will need to restart each nsqd instance with updated configuration.
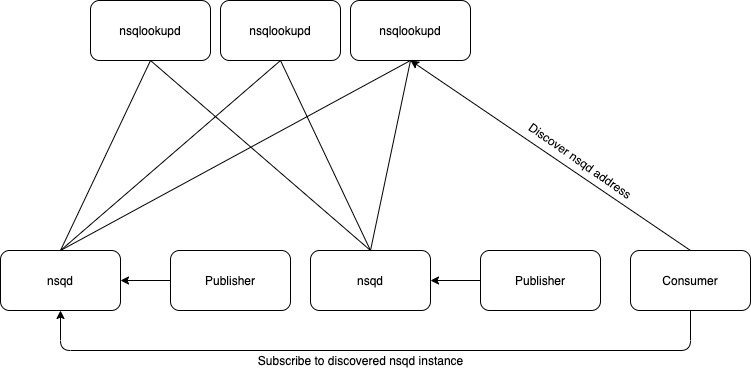
Example install: publishers publish to an instance of nsqd installed along side them & consumers leverage nsqlookupd to find the appropriate instance to consume from.
Enough! let’s get it running
First, create a docker-compose config named docker-compose-nsq.yml with the following content:
version: '3'
services:
nsqlookupd:
image: nsqio/nsq
hostname: nsqlookupd
ports:
- "4160:4160"
- "4161:4161"
command: /nsqlookupd
nsqd:
image: nsqio/nsq
hostname: nsqd
ports:
- "4150:4150"
- "4151:4151"
command: /nsqd -broadcast-address=nsqd --lookupd-tcp-address=nsqlookupd:4160
nsqadmin:
image: nsqio/nsq
hostname: nsqadmin
ports:
- "4171:4171"
command: /nsqadmin --lookupd-http-address=nsqlookupd:4161And that’s it! Now you can start the NSQ cluster:
docker-compose -f docker-compose-nsq.yml up
If you want, you can navigate to the admin web app in your browser http://localhost:4171/ to poke around and confirm everything is connected right.
So what’s going on in that docker-compose config?
The first thing you might notice is all three containers leverage the same
nsqio/nsq docker image. Conveniently, the folks at NSQ have packaged all the NSQ apps
and utilities into one image so it’s easy to keep track of things: just target the appropriate
app in your command.
Let’s look at each service and see how it’s joining the cluster:
nsqlookupd
nsqlookupd is the most straight forward because it’s our discovery mechanism,
so it just needs to run at a known address. We run the app with no
args and expose the ports it’s listening on: 4160 for low level TCP communication
with clients & 4161 for its REST api over http.
The nsqd nodes of the cluster communicate over the low level tcp port
to coordinate their membership in the cluster and the consumer app we will
create later will connect with the REST api to discover the rest of the cluster.
nsqd
nsqd also has a port open for low level TCP communication (4150) and one for
its REST api over http (4151). It additionally offers an option to listen to https traffic
on port 4152, but we aren’t going into that here.
The nsqd service has to join the cluster to be useful. We can accomplish this with the
flag --lookupd-tcp-address=nsqlookupd:4160 which configures a lookupd address
for nsqd to join the cluster through (this flag should be used multiple
times if you have multiple lookupd instances.)
In addition to joining, nsqd needs to declare how it can be reached and does so with
the flag -broadcast-address=nsqd (which defaults to hostname which in our case happens to be what we want,
but I included it anyway to be explicit)
docker-compose sets up networking so that containers can be reached via their hostname so we can use the container’s hostname as its address and it will resolve appropriately.
nsqadmin
nsqadmin isn’t a part of the cluster’s function, but still needs to discover it so
that the details can be inspected and exposed. We configure that connection with our
lookupd’s http address using the --lookupd-http-address=nsqlookupd:4161 flag.
In addition, it needs to expose the http port that the web server is running on (4171) so we can navigate to it in a web browser.
see all the flags and options on NSQ’s documentation page
Sending & Receiving Messages
As for actually using NSQ, all you need to understand are topics and channels.
Each nsqd instance can have multiple topics, and each topic can have
one or more channels. Messages are published to a topic and each channel for that
topic receives a copy of the message. Messages can then be received by subscribing to
a channel. In other words, message producers publish messages to a topic
and message consumers consumer messages from a channel on a topic. You don’t even
need to create these topics and channels as separate steps: they are established
when they are first published or subscribed to.
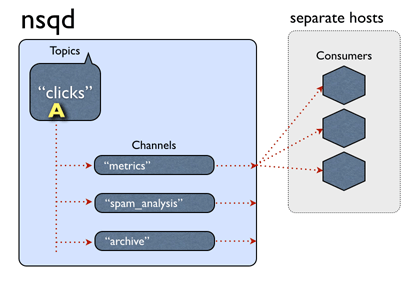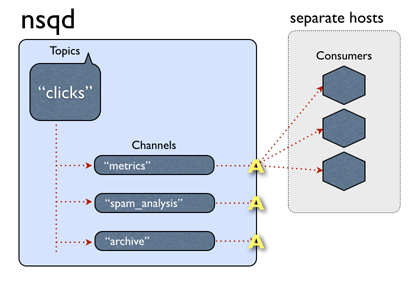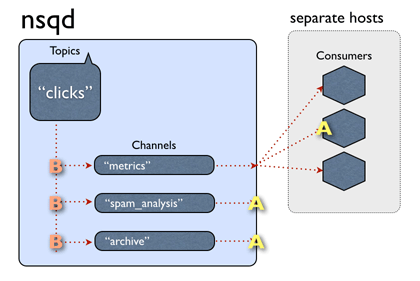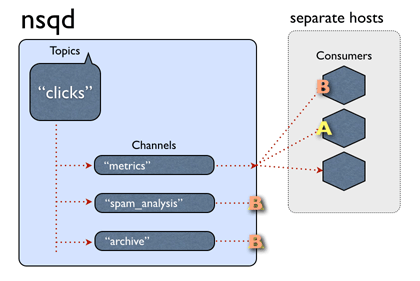
How messages are routed (shamelessly stolen from the NSQ docs page)
Producer
Lets start by sending some messages.
Again, follow along here or clone the demo repo off Github
package main
import (
"flag"
"log"
"os"
"github.com/nsqio/go-nsq"
)
var (
addr = flag.String("addr", "localhost:4150", "NSQ addr")
topic = flag.String("topic", "", "NSQ topic")
message = flag.String("message", "", "Message body")
)
func main() {
// parse the cli options
flag.Parse()
if *topic == "" || *message == "" {
flag.PrintDefaults()
os.Exit(1)
}
// configure a new Producer
config := nsq.NewConfig()
producer, err := nsq.NewProducer(*addr, config)
if err != nil {
log.Fatal(err)
}
// publish a nessage to the producer
err = producer.Publish(*topic, []byte(*message))
if err != nil {
log.Fatal(err)
}
// disconnect
producer.Stop()
}And send a message (even though nobody’s listening yet)
$ go run cmd/producer/producer.go -topic test -message "hello world"
2020/09/17 09:35:43 INF 1 (localhost:4150) connecting to nsqd
2020/09/17 09:35:43 INF 1 stopping
2020/09/17 09:35:43 INF 1 (localhost:4150) beginning close
2020/09/17 09:35:43 INF 1 (localhost:4150) readLoop exiting
2020/09/17 09:35:43 INF 1 (localhost:4150) breaking out of writeLoop
2020/09/17 09:35:43 INF 1 (localhost:4150) writeLoop exiting
2020/09/17 09:35:43 INF 1 exiting router
Consumer
OK! Now let’s consume that message we just published to the “test” topic.
package main
import (
"flag"
"log"
"os"
"os/signal"
"syscall"
"github.com/nsqio/go-nsq"
)
var (
addr = flag.String("addr", "nsqlookupd:4161", "NSQ lookupd addr")
topic = flag.String("topic", "", "NSQ topic")
channel = flag.String("channel", "", "NSQ channel")
)
// MyHandler handles NSQ messages from the channel being subscribed to
type MyHandler struct {
}
func (h *MyHandler) HandleMessage(message *nsq.Message) error {
log.Printf("Got a message: %s", string(message.Body))
return nil
}
func main() {
// parse the cli options
flag.Parse()
if *topic == "" || *channel == "" {
flag.PrintDefaults()
os.Exit(1)
}
// configure a new Consumer
config := nsq.NewConfig()
consumer, err := nsq.NewConsumer(*topic, *channel, config)
if err != nil {
log.Fatal(err)
}
// register our message handler with the consumer
consumer.AddHandler(&MyHandler{})
// connect to NSQ and start receiving messages
//err = consumer.ConnectToNSQD("nsqd:4150")
err = consumer.ConnectToNSQLookupd(*addr)
if err != nil {
log.Fatal(err)
}
// wait for signal to exit
sigChan := make(chan os.Signal, 1)
signal.Notify(sigChan, syscall.SIGINT, syscall.SIGTERM)
<-sigChan
// disconnect
consumer.Stop()
}We just ran the producer on our host machine, but since we set up our nsqd daemon
to broadcast on its docker-compose managed hostname, let’s run the consumer with
docker-compose as well to make finding it easier.
First, build a docker image with the following Dockerfile:
FROM golang:latest
RUN mkdir /app
ADD . /app/
WORKDIR /app
RUN go build ./cmd/consumer
CMD ["/app/consumer"]docker build -t nsq-consumer -f Dockerfile-consumer .
And now create a docker-compose config
version: '3'
services:
consumer:
image: nsq-consumer
command: /app/consumer -topic test -channel foo$ docker-compose -f docker-compose-consumer.yml up
Starting nsq-demo_consumer_1 ... done
Attaching to nsq-demo_consumer_1
consumer_1 | 2020/09/17 14:44:49 INF 1 [test/foo] querying nsqlookupd http://nsqlookupd:4161/lookup?topic=test
consumer_1 | 2020/09/17 14:44:49 INF 1 [test/foo] (nsqd:4150) connecting to nsqd
consumer_1 | 2020/09/17 14:44:49 Got a message: hello world
Success! Publish a few more messages and our consumer should receive those too.
Let’s walk through what happened:
- In our publisher, we published a message to the topic
testwhich created the topic on thensqdinstance we have running and added the message to it - When we started our consumer, it performed a lookup using
nsqlookupdto find the instance ofnsqdthat had the topic we were looking for (test). This isn’t particularly useful with only one instance of course, but pretend…- In the
consumer.gocode, you can see the commented out line that would have connected directly to to thensqdserver without the intermediatensqlookupdlookup. This would have been fine in our simple example, but fails to illustrate how it would work in a distributed system.
- In the
- Having found the topic, the consumer created a channel named
foowhich will now receive a copy of every message sent to thetesttopic. - Finally, we were delivered the message we sent earlier.
Worker Pattern
The worker pattern is a strategy where you employ a single queue to manage tasks that need to be performed that you don’t have to wait on to complete. This is especially useful when the task is resource or time intensive. With worker queues (or task queues) your publishers can queue up work and then move on to other things while consumers pull work off the queue and perform it. This pattern also allows you to effectively scale how many consumers you have without scaling your producers. Even waiting around for another service to complete work can impact your work producer’s ability to handle new traffic, but by decoupling the service doing the work from the one identifying that it needs to be done with a message queue, the work producer can move on to it’s next job.
A simple example of this is sending email. Many different workloads may need to send email, so it makes sense to encapsulate that operation in its own service, but typically we don’t care when exactly the email is sent out. By leveraging a work queue as our email service’s interface, our software and queue up email on a message queue and move on to other things knowing that our email service will consume those email messages and ensure they get sent. They can even implement retrys by returning messages to the queue if for example a destination mail server is not available for some reason.
So what does that look like in practice? Let’s set up a couple of “email services” with docker compose and send some email (actually, we’ll just use the same producer & consumer applications from above, but imagine they’re doing actual work.)
version: '3'
services:
worker1:
image: nsq-consumer
command: /app/consumer -topic email -channel default
worker2:
image: nsq-consumer
command: /app/consumer -topic email -channel defaultYour first inclination might be to start your consumers (the email service) first so you don’t miss any messages, but since the topic hasn’t been created yet you won’t be able to locate it. To solve for this, publish a throwaway message before starting your consumers (or head over to the admin web app and create the new “email” topic manually.)
In one terminal, run your consumers with docker-compose
docker-compose -f docker-compose-worker.yml up
and in another, start publishing “emails”
go run cmd/producer/producer.go -topic email -message "hello world"
go run cmd/producer/producer.go -topic email -message "hello world"
go run cmd/producer/producer.go -topic email -message "hello world"
As you can see from our logs, both consumers connect to nsqd and take turns
handling messages as they showed up.
worker2_1 | 2020/09/18 14:17:07 INF 1 [email/default] querying nsqlookupd http://nsqlookupd:4161/lookup?topic=email
worker2_1 | 2020/09/18 14:17:07 INF 1 [email/default] (nsqd:4150) connecting to nsqd
worker1_1 | 2020/09/18 14:17:07 INF 1 [email/default] querying nsqlookupd http://nsqlookupd:4161/lookup?topic=email
worker1_1 | 2020/09/18 14:17:07 INF 1 [email/default] (nsqd:4150) connecting to nsqd
worker2_1 | 2020/09/18 14:17:11 Got a message: hello world
worker1_1 | 2020/09/18 14:17:12 Got a message: hello world
worker2_1 | 2020/09/18 14:17:14 Got a message: hello world
Pub/Sub Pattern
The worker pattern above provides scalability, resiliency, and performance gains to a pretty familiar pattern (it’s basically an rpc call implemented with different technology and lacking a response), but pub/sub is something fundamentally different.
Pub/sub is a powerful strategy for managing how your software is coupled. It works like the observer pattern, allowing multiple observers to to register their desire to be notified when a subject changes without the subject being aware of them. This way as you add new observers of the subject you won’t develop complexity hot spots by integrating with n observers in the subject’s code.
With Pub/sub, your producer (subject) can publish events to a topic and n consumers (observers) can subscribe using a unique channel to get their own copy of the event. Additionally, horizontal scaling can still be achieved by attaching multiple consumers to the same channel.
In the following example, we’ll build a hypothetical order processing application. Our producer will send out an event message when an order is placed, and we will have two groups of consumers subscribed to this event: one to start fulfilling the order and another to email a confirmation message to the customer. (Again, we’ll be using the same producer & consumer code from above and just naming our topic and channels to simulate the design)
Another thing to note here: you can either sent the whole order object in your message or just a reference to it. It depends if you are just leveraging this design to decouple your subscribers from the subject firing the event, or if you are trying to build a pipeline that doesn’t need to query for additional information.
version: '3'
services:
pubsub_fulfillment1:
image: nsq-consumer
command: /app/consumer -topic orders_placed -channel fulfillment
pubsub_fulfillment2:
image: nsq-consumer
command: /app/consumer -topic orders_placed -channel fulfillment
pubsub_email_confirmation1:
image: nsq-consumer
command: /app/consumer -topic orders_placed -channel email_confirmation
pubsub_email_confirmation2:
image: nsq-consumer
command: /app/consumer -topic orders_placed -channel email_confirmationJust as before, either publish a throwaway message before starting your consumers, or head over to the admin web app and create the new “orders_placed” topic manually.
In one terminal, run your consumers with docker-compose
docker-compose -f docker-compose-pub-sub.yml up
and in another, start publishing “orders”
go run cmd/producer/producer.go -topic orders_placed -message "order 123"
go run cmd/producer/producer.go -topic orders_placed -message "order 124"
go run cmd/producer/producer.go -topic orders_placed -message "order 125"
Looking at our logs, we can see that each order was delivered to each of the two consumer roles so each order can be fulfilled and have an email autoresponse sent.
pubsub_fulfillment1_1 | 2020/09/18 14:54:56 Got a message: order 123
pubsub_email_confirmation2_1 | 2020/09/18 14:54:56 Got a message: order 123
pubsub_fulfillment2_1 | 2020/09/18 14:54:58 Got a message: order 124
pubsub_email_confirmation1_1 | 2020/09/18 14:54:58 Got a message: order 124
pubsub_email_confirmation2_1 | 2020/09/18 14:55:00 Got a message: order 125
pubsub_fulfillment1_1 | 2020/09/18 14:55:00 Got a message: order 125
In Conclusion…
Messaging is a powerful tool for building async architectures and NSQ makes it easy to get started. While it isn’t a fit for all systems because of the high degree of orchestration required to keep everything discoverable and availablle in larger setups, for usecases that need fast and easy to manage messaging but don’t require guarantees of durability or availability it is hard to top.
comments powered by Disqus